AWS S3 SelectをJSONでやってみました
最近発表されたAWSの新機能S3Selectがプレビュー申し込みしたら、翌日には許可されたので試してみました。
そこで実行するまで紆余曲折があったのでメモ。
S3 selectについて
このようにS3に保存されたデータの検索をSQLで行うことが出来るようになります。
所感としてはAthenaっぽいですが、Athenaより単機能で高速という感じです。
SELECTしかしない。というならこちらのほうが良さそうですが、まだまだ使い勝手がよくわかりません。
そのうちAthenaにも組み込まれるようなので、こうご期待です(´ω`)
S3 SELECTのドキュメントはこちら
http://docs.aws.amazon.com/ja_jp/AmazonS3/latest/API/RESTObjectSELECTContent.html
ドキュメントを読んでみると、
GROUP BY is not supported.
とのことなので、集計向きではない感じですが、
ギリギリCOUNTは使えるようなので、シンプルな使い方として取り敢えずJSONデータの件数を出せるようにしてみます。
準備
今回はPythonで行いますので、下記URLをご参照ください。
http://s3select.s3-website-us-east-1.amazonaws.com/public/python/SelectObjectContentUsingPython.html
サクッと試すのであれば同じく発表されたCloud9 のEC2インスタンス上で行うのが楽です。
ターミナル上で下記を実行します。
[bash]
wget http://s3select.s3-website-us-east-1.amazonaws.com/public/python/aws-python-sdk-s3-select-preview-1.0.0.zip
unzip aws-python-sdk-s3-select-preview-1.0.0.zip
[/bash]
そうすると「aws-python-sdk-s3-select-preview-latest」ディレクトリが生成されるので、cdで移動しておきます。
また、今回boto3を利用するので下記でインストールしておきます。
[bash]sudo pip install boto3[/bash]
これで準備完了。
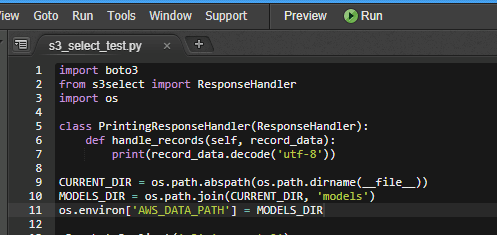
下記サンプルコードです。
実装
[python]
import boto3
from s3select import ResponseHandler
import os
class PrintingResponseHandler(ResponseHandler):
def handle_records(self, record_data):
print(record_data.decode('utf-8’))
CURRENT_DIR = os.path.abspath(os.path.dirname(__file__))
MODELS_DIR = os.path.join(CURRENT_DIR, 'models’)
os.environ['AWS_DATA_PATH’] = MODELS_DIR
s3 = boto3.client('s3′,’us-west-2′)
response = s3.select_object_content(
Bucket=’s3selecttest’,
Key=’getstream-3-2017-12-03-00-55-12-f9953d2b-e25e-4a2d-a53d-a221026f7e23′,
SelectRequest={
'ExpressionType’: 'SQL’,
'Expression’: 'Select COUNT(*) AS cnt FROM S3Object’,
'InputSerialization’: {
'CompressionType’: 'NONE’,
'JSON’: {
'Type’:’Lines’
}
},
'OutputSerialization’: {
'JSON’: {
'RecordDelimiter’:’\n’
}
}
}
)
handler = PrintingResponseHandler()
handler.handle_response(response['Body’])
[/python]
結果
[bash]
{"cnt":132}
[/bash]
今回自分のサンプルでは132個見つけたようです。
注意点
公式ニュース記事のサンプルコードは仮のものです。APIドキュメントの方を参照してくださいね(´ω`)。
https://aws.amazon.com/jp/blogs/aws/s3-glacier-select/
このプレビューは、米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、欧州 (アイルランド)、およびアジアパシフィック (シンガポール) の AWS リージョンで利用できます。このプレビューは、米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、欧州 (アイルランド)、およびアジアパシフィック (シンガポール) の AWS リージョンで利用できます。
・・・大事なことなので二回言っているのですかね(´ω`;)
東京リージョンでは利用できません。
上記の利用出来ないというのはS3バケットのリージョンも該当します。
S3だとコンソール画面のリージョン選択がこんな感じ
なので、意識しないかもしれません(僕はそうでした・・・)
未対応の東京リージョンバケットを指定していると下記エラー
[bash]
An error occurred (MethodNotAllowed) when calling the SelectObjectContent operation: The specified method is not allowed against this resource.
[/bash]
権限か、権限なのか?とさまよっていたところ・・・
こちらのブログを拝見して( ゚д゚)ハッ!としました。
「S3 Selectを試してみた #aws #jawsug」
https://www.totalsolution.biz/s3-select_first_impression/
ようやく出来た・・・(ヽ´ω`)
また、APIリファレンスには必須ではない。と書かれていますが、下記コード
[python]
'InputSerialization’: {
'CompressionType’: 'NONE’,
'JSON’: {
'Type’:’Lines’
}
},
'OutputSerialization’: {
'JSON’: {
'RecordDelimiter’:’\n’
}
}
[/python]
Input,OutputともにJSONを指定している場合は一応このように中身を入れてあげる必要があります。
サンプルのほとんどがCSVなのでちょっとつまづきました。
今はAPIのみですが、コンソールで出来るようになると、気軽に膨大なログの特定キーワードだけ抽出とか使いようはありそうですね。
以上シンプルですが、S3Selectのレビューです(・ω・)ノ