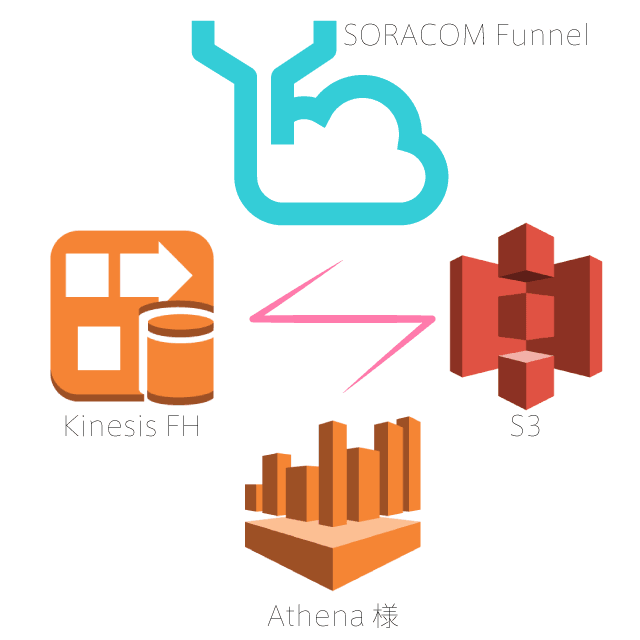
SORACOM FunnelからAmazon Kinesis Firehoseを使ってS3へ保存。してからのAthenaで集計したい!
長めのタイトルとなりました。
最近はIoTも勉強中のくろにゃんこたんです。
タイトルどおりなのですが、
SORACOM FunnelからAmazon Kinesis Firehoseを使ってS3へ保存。
ここまでは、非常に簡単に設定出来ます。
SORACOM Funnel の Kinesis Firehose アダプターを使用してクラウドにデータを収集する(コンソール版)
S3に保存してしまえば後はなんとでも出来てしまいますが、2017/11/06現在上記ブログに一つだけミスリードがあります。
[bash]
{"operatorId": "OP0026965167", "timestamp": 1455672330494, "destination": {"resourceUrl": "https://firehose.us-west-2.amazonaws.com/my-kinesis-firehose01", "service": "firehose", "provider": "aws"}, "credentialsId": "my-aws-credentials", "payloads": {"message": "Hello SORACOM Funnel via TCP!"}, "sourceProtocol": "tcp", "imsi": "440XXXXXXXXXX"}
{"operatorId": "OP0026965167", "timestamp": 1455672351248, "destination": {"resourceUrl": "https://firehose.us-west-2.amazonaws.com/my-kinesis-firehose01", "service": "firehose", "provider": "aws"}, "credentialsId": "my-aws-credentials", "payloads": {"message": "Hello SORACOM Funnel via UDP!"}, "sourceProtocol": "udp", "imsi": "440XXXXXXXXXX"}
{"operatorId": "OP0026965167", "timestamp": 1455672363539, "destination": {"resourceUrl": "https://firehose.us-west-2.amazonaws.com/my-kinesis-firehose01", "service": "firehose", "provider": "aws"}, "credentialsId": "my-aws-credentials", "payloads": {"message": "Hello SORACOM Funnel via HTTP!"}, "sourceProtocol": "http", "imsi": "440XXXXXXXXXX"}
[/bash]
S3に保存されているデータは、連続してKinesisに突っ込んだ場合、バッファリングを得てS3に格納されます。
そのバッファ以内(例えば60秒以内に)複数件送った場合形式としては、ようするに下記の様になります。
[bash]
{"operatorId": "OP0026965167", "timestamp": 1455672330494, "destination": {"resourceUrl": "https://firehose.us-west-2.amazonaws.com/my-kinesis-firehose01", "service": "firehose", "provider": "aws"}, "credentialsId": "my-aws-credentials", "payloads": {"message": "Hello SORACOM Funnel via TCP!"}, "sourceProtocol": "tcp", "imsi": "440XXXXXXXXXX"}{"operatorId": "OP0026965167", "timestamp": 1455672351248, "destination": {"resourceUrl": "https://firehose.us-west-2.amazonaws.com/my-kinesis-firehose01", "service": "firehose", "provider": "aws"}, "credentialsId": "my-aws-credentials", "payloads": {"message": "Hello SORACOM Funnel via UDP!"}, "sourceProtocol": "udp", "imsi": "440XXXXXXXXXX"}{"operatorId": "OP0026965167", "timestamp": 1455672363539, "destination": {"resourceUrl": "https://firehose.us-west-2.amazonaws.com/my-kinesis-firehose01", "service": "firehose", "provider": "aws"}, "credentialsId": "my-aws-credentials", "payloads": {"message": "Hello SORACOM Funnel via HTTP!"}, "sourceProtocol": "http", "imsi": "440XXXXXXXXXX"}
[/bash]
改行がされてないんです!
ここはSORACOM中の人のせいと言うよりはAWS側の問題とのことらしいのですが、、、
このデータをそのままPHPでも良いので処理したい場合は単純に
[PHP]
str_replace(“}{“,"}\n{“,$data));
[/PHP]
的な処理でもなんとかなってしまいます。
ですが、タイトルにもある通り、「Athena」ではエラーとなります。
単純に改行だけしてくれれば集計が出来るのに(ヽ´ω`)
ということでその為だけにLambdaを使うことが必須になります。
Amazon Kinesis Firehoseのコンソールにて「Data transformation*」を「Enabled」へ変更。
lambda関数を新規作成します。
案外改行「だけ」追加するのコードが探しても見つからなかったので、恐る恐るサンプルコードとにらめっこしながら改行コードを追加します。
処理としては単純で、BASE64で来たデータを一度デコードして、改行コードをくっつけて、エンコード。とこれだけです。
(ちなみにAPI gatewayとか使うならこんなことせずにVTLでなんとかなります。。。)
python2.7で書きました。
[python]
from __future__ import print_function
import base64
def lambda_handler(event, context):
output = []
for record in event['records’]:
print(record['recordId’])
payload = base64.b64decode(record['data’])
# Print stream as source only data here
# Do custom processing on the payload here
output_record = {
'recordId’: record['recordId’],
'result’: 'Ok’,
'data’: base64.b64encode(payload)+’Cg==’
}
output.append(output_record)
print('Successfully processed {} records.’.format(len(event['records’])))
return {'records’: output}
[/python]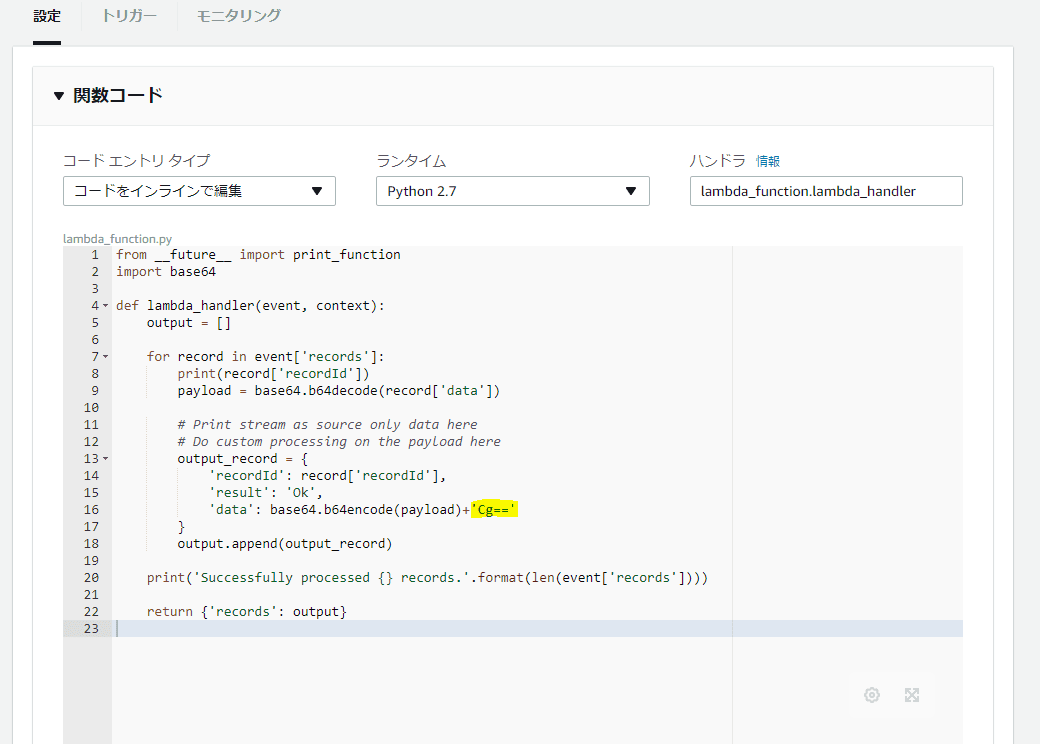
上記画像にもある通り「’Cg==’」を追加するだけです。
もっと良いコードがあると思いますので、募集中です。
ちなみにlambdaのレスポンスは下記の通り
[bash]
Duration: 0.39 ms
Billed Duration: 100 ms
Memory Size: 128 MB
Max Memory Used: 19 MB
[/bash]
lambdaは0.39ms/100msなら許容範囲内かと・・・
一応lambdaにもレートリミットがあるのですが、、、
そのクラスの量のデータが来たら、Kinesisの方で大幅にスロットリングするので、そこから考えましょう(´ω`;)
ちなみにKinesisの通常リミットは4000件/secとなっています。
これを超えるようならスケーリングとリミットを上げる為のケースを作ります。(ここは長くなるのでまた別の話で)
(もっというと、ぶっちゃけいきなり4000件も1秒間にドサッとデータを飛ばして上げると、この制限よりもっと前にtimeoutエラーが発生しますけどね)(ここは長くなるのでまた別の話で)
これでようやくAthenaで集計出来るようになりました(´ω`)
ちなみによくIoTの設計パターンとして、何でもかんでもRDSやDynamoDBにすぐに突っ込みたくなるのをよく見ますが、
そこはもう少し運用を考えてゆとりを持ったものにすると、ぐっと少ないランニングコストで運用出来るようになります。
追記:画像を変更しました。ZよりSだよなと思い直しました(・ω・;)
